
LevelDB WAL log - extracting ChatGPT conversations
Write-ahead log analysis

Background
ChatGPT desktop app uses LevelDB's write-ahead logging (WAL) mechanism to temporarily store the cache of conversation history.
The WAL log is written to disk after ChatGPT application (i.e. associated process tree) is terminated, which may happen either at system shutdown/reboot or if the user exits the application. The exact location of the binary: “%UserProfile%\AppData\Local\Packages\OpenAI.ChatGPT-Desktop_2p2nqsd0c76g0\LocalCache\Roaming\ChatGPT\IndexedDB\https_chatgpt.com_0.indexeddb.leveldb\######.log” (“000003.log” in my case).
The log will stay on disk until the user loggs off from the ChatGPT account within the app. When that happens, the contents of “https_chatgpt.com_0.indexeddb.leveldb\” will be erased.

When the user logs back into the app, the contents of “https_chatgpt.com_0.indexeddb.leveldb\” will be re-created, however, no conversation log will be present in “000003.log”. If you select any of the historical conversations within the ChatGPT app, their contents will be written in a structured way into “000003.log”. Thus, we can potentially distinguish between conversations that were entered directly into the app and historical conversations that the user accessed.
Limitations
ChatGPT desktop app version 1.2025.021.
Lab operating system: Windows 10 Pro, version 21H2, OS build “19044.1766”.
Tests were performed on a freshly installed ChatGPT desktop application. That means if there was a heavy usage of the app, some behaviors may change. LevelDB is known for utilizing WAL as a temporary storage. When the log file reaches 4MB in size, the contents of the WAL binary will be written to a LevelDB database binary (.ldb), as referenced in the article by Alex Caithness (please refer to References section for the article link).
WAL binary structure
Initial processing
To streamline the analysis of the WAL log I leveraged “leveldbutil” application’s “dump” option. This helps to parse the log and present it in more structured format, that we can leverage in both manual and automated analysis.

Here are some of the patterns that can be immediately spotted:
The data is written in chunks divided by “--- offset #; sequence #” separator. Each chunk contains a set of operations that are executed simultaneously. For example, at offset 0 we only have one operation, however at offset 308 we can see that 20 operations were executed.
“offset #” - indicates the byte position in the file where each database record starts.
“sequence #” - a monotonically increasing number that preserves the order of operations, and each operation gets a unique sequence number. The operations can be “put” and “del”.
“put” - database operation that adds or updates a key-value pair in the database, with the format is typically being "put 'key' 'value'“, e.g. “put '\x00\x00\x00\x002\x00' '\x08\x01'“ from the Figure 2 screenshot.
“del” - database operation that removes a key-value pair from the database, with the format is typically being “del 'key'“, e.g. “del '\x00\x00\x00\x002\x01\x0c'“ from Figure 3 screenshot.

Initial conversation record
The WAL log shows that ChatGPT begins writing conversations at offset 1816 (please refer to Figure 4 down below), assuming no cached offline conversation records are present (as explained in the "LevelDB WAL" section of this post). Looking at the set of operations, analyst can extract the following valuable information:
Conversation ID has a pattern that can be matched with the following regex: “$[a-z0-9]{8}\-([a-z0-9]{4}\-){3}[a-z0-9]{12}” (e.g. $6797fd67-a208-800e-ae5c-5bbd51abf7ad). Conversation ID can be used in automation to correlate all messages from the same conversation.
Authenticated user ID has a pattern that can be matched with the following regex: “\x0aauthUserId"\x1d(user-[^"]+)” (e.g. authUserId"\x1duser-DprP7QKdmuYYyxFV20428vJK). I noticed two patterns in the log - “authUserId” and “accountUserId”. The value in “authUserId” would also be present within “accountUserId” field. In the parser script I export the value of “authUserId”. Each chunk of WAL log (i.e. the set of operations prefixed by “--- offset #; sequence #” separator) that contains conversations, would also store both user auth ID and conversation ID. This comes in handy when we want to parse the log and reconstruct the conversation sequence automatically.
Title, which is empty for now. That’s consistent with the application behavior, the title will only be generated after the initial assistant response.
The conversation start time is recorded in the “updateTime” field. Looking at the structure we can see the time stamp is recorded with the following values: “\xa0\x1a\x87W\xff\xe5\xd9A”. The timestamp format is IEEE 754 double-precision floating point number in little-endian format and can be decoded into “2025-01-27T21:40:46.111000 UTC”. In my tests, this time stamp remained intact even after I continued the same conversation after ChatGPT application restarted on the following day. This timestamp represents the date and time when the conversation started. Timestamps will be preserved per conversation, meaning if a single WAL log has multiple conversations, each will have its time stamp. The following regex will match the time stamp pattern: “updateTimeN((?:\x[0-9a-f]{2}|[\x20-\x7E]){8})”.
The very first user prompt is distinguished from follow-up prompts, and it can be matched with the following regex: “root-nextPrompt"\x04text"([^{]+)” (e.g. root"root-nextPrompt"\x04text"\x13Hello, how are you?”). I want to point out an interesting pattern that is perceived by all messages in the log - they would be ending with opening curly brackets “{“. This pattern can be used to match the end of each message within a conversation. Hereinafter, I will be referring to the human that enters prompts as “user”, and the ChatGPT application responses will be called “assistant” responses.
The very first assistant response. This is also one of our first pain points when we talk about automation. The responses can be either ASCII (when the assistant responds just with text), or either UTF-8 or UTF-16 (when the assistant adds non-ASCII characters, like emojis, for example). Please refer to Figure 4 as an example, where the response was encoded in UTF-16. Note that assistant responses contain message ID, we will revisit this behavior later.

Conversation title
Let’s look at the WAL log offset 3915, where the application recorded the very first occurrence of the conversation title:
We can see the previously observed fields, including conversation ID, timestamp, first user prompt, and first assistant response. Generally speaking, within the WAL log there will be many duplicative entries for the messages, so I added deduplication logic to my script.
However, now the “title” field is not empty and shows the actual title of the conversation. The regex we can use here is “(?<=\x05title"\)(.*?)(?=\x0aisArchivedF")”, thus we avoid situations when the word “title” could appear within either user’s or assistant’s messages.

Follow-up user prompts
The non-initial prompts that were entered by the user, have similar structure as initial prompt:
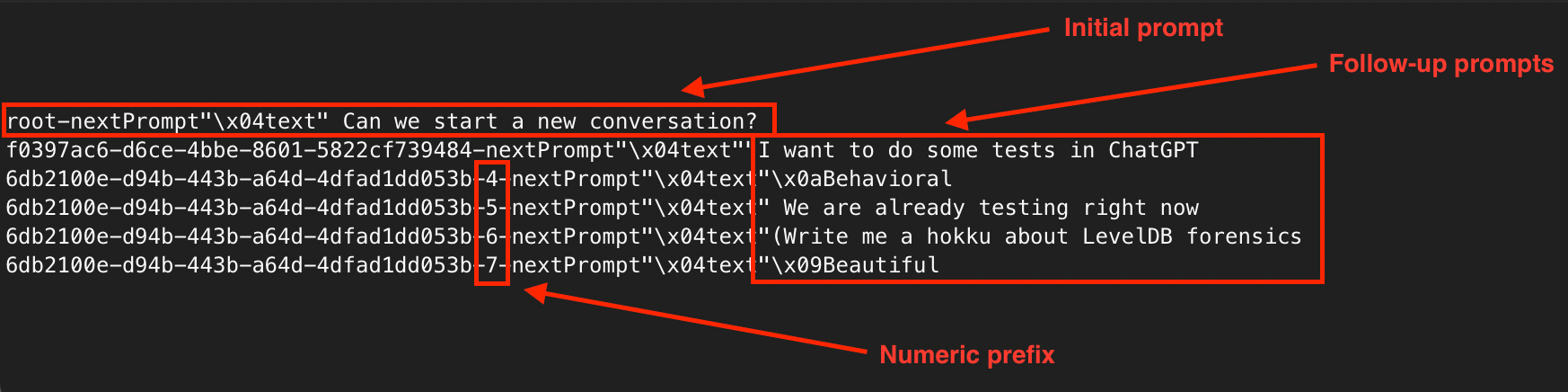
The prompts start with “nextPrompt” followed by the message that ends with “{“. However, unlike the initial message that has “root-” prefix, the follow-up messages would contain an ID prefix in GUID format.
In some cases, there will be a numeric indicator between the GUID and the message (please refer to Figure 6).
The follow-up prompts can be captured with the following regex: “(?<!root-)nextPrompt"\x04text"([^{]+)(?={)”.
Note the GUID ID pattern prior to the messages! We’ll revisit this later.
Follow-up assistant responses
The non-initial assistant responses also have a similar pattern to the initial response:
The messages start with “request-WEB” followed by GUID ID. Assistant messages can sometimes be encoded with UTF-16, UTF-8, or have extra hex characters. I had to create a list of regex patterns that I observed through my tests. This may result in situations when assistant responses would not be properly captured by my script.
In some cases, there will be a numeric indicator that shows the position of response (please refer to Figure 7).
Again note the GUID ID pattern here too!

Conversation thread ID
Remember those GUIDs we saw in the “Follow-up user prompts“ and “Follow-up assistant responses“ sections above?
The conversation thread ID is a theoretical term that I came up with. Thread IDs can be used by ChatGPT desktop application to keep track of various conversation threads within the parent conversation. Please refer to Figure 8 for the complete set of messages shared between the user and assistant, showing conversation thread IDs.
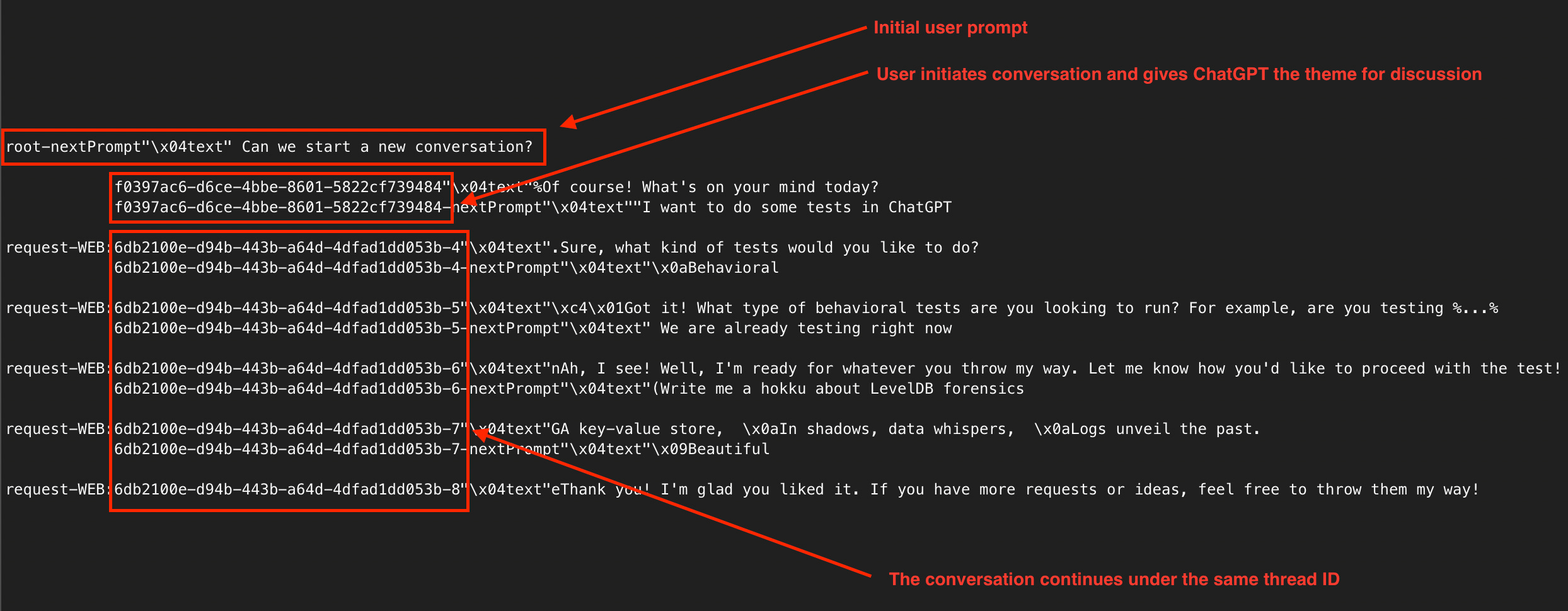
I did another test where I changed the topic in the middle of our conversation with ChatGPT. Please refer to Figure 9, where you can see how the conversation thread ID changes when ChatGPT determines the user changing the topic.

Proof-of-concept code
I wrote a PoC script designed to parse and analyze LevelDB WAL file generated by the ChatGPT application. The script will extract conversations, reconstructing the chat history and metadata, including time stamps. The script is leveraging “leveldbutil” application to dump the WAL contents. With that said, you should install “leveldbutil” application in order for the script to work.
The script leverages a series of regex patterns to extract conversation components, user/assistant messages, timestamps, and other metadata by matching specific byte patterns in the WAL entries. The script maintains message ordering and prevents duplicates by tracking message positions and using a deduplication mechanism with normalized message content.
WAL log is complex and may encode data in ASCII, UTF-8, and UTF-16, depending on the chat contents, in addition to that, the format of messages may change and have special characters. The parsed data is organized into a structured format, with each conversation containing a title, user ID, timestamp, and a chronological sequence of messages. The output can be dumped into the “conversations.json” file.

Please note the script is still a PoC and work-in-progress, it will require additional improvements and enhancements. One of the potential improvements is leveraging conversation thread IDs for reconstructing and orderin.
References
The theme for this post was inspired by David Cowen’s Sunday Funday challenge! Join the cult and submit your posts too! (https://www.hecfblog.com/2025/01/daily-blog-730-sunday-funday-12625.html)
“Hang on! That’s not SQLite! Chrome, Electron and LevelDB” by Alex Caithness (https://www.cclsolutionsgroup.com/post/hang-on-thats-not-sqlite-chrome-electron-and-leveldb)
“LevelDB” by Ju Chen (https://chenju2k6.github.io/blog/2018/11/leveldb)
Tools used
chat_gpt_wal_parser (https://github.com/ilyakobzar/dfir-tools/blob/main/chat_gpt_wal_parser.py)
leveldbutil (https://github.com/google/leveldb)
X-Ways Forensics (https://www.x-ways.net/forensics/index-m.html)
I have tried to use your script, and it seems like the version of leveldbutil that is available now does not support the way you have used the dump utility. When did you initially clone leveldbutil? I am trying to look back to see if I can clone an old version to use instead. Great article! Thanks